


Préambule
Il ne fait plus l’ombre d’un doute … si vous travaillez dans le SEO vous allez (ou ça viendra) être confronté au JavaScript. Pour de nombreux SEO (purement métier), le JavaScript est synonyme d’angoisse. Cet article tente d’apporter des solutions voire des clarifications autour de certaines croyances.
Dans cet article, nous verrons :
- Qu’est ce que le JavaScript ?
- Comment fonctionne le JavaScript ?
- Comment savoir si mon site utilise du JS ?
- Comment Google interprète le JavaScript ?
- Comment vérifier si votre site Web a un problème avec JavaScript ?
- Quelles sont les meilleures pratiques du référencement JavaScript
TL;DR
- Le Javascript améliore l’UX mais complexifie l’exploration des pages pour Googlebot
- L’exploration du contenu HTML est chose aisée pour Google. Lorsqu’il s’agit de contenus propulsés par du JS, le temps d’exploration est rallongé.
- Utilisez l’extension Chrome « Web Developer » pour désactiver le JS et vérifier que le contenu de vos pages s’affichent correctement.
- Consulter le cache Google d’une page (webcache:url) ou le code source n’est pas une bonne pratique pour vérifier si le contenu généré par du JS est perçu par Google. Privilégiez une vérification soit du DOM (inspecter l’élément) soit de la Search Console (afficher la page explorée) ou enfin la commande Google « mytext site:mywebsite »
- Googlebot utilise la dernière version de Chrome pour explorer les pages. Cependant il se réserve le droit d’exécuter certaines ressources.
- 4 approches pour rendre « seo compliant » vos contenus propulsés par du JavaScript : Le pre-rendering – le SSR (server side rendering) – le dynamique rendering, le rendu hybride.
Qu’est-ce que JavaScript et comment est-il utilisé?
En 2020, cela ne fait aucun doute, le JavaScript est (presque) partout. La plupart des sites web les plus connus exploitent des librairies JS. Le JavaScript est un langage de programmation extrêmement populaire. Il est utilisé par les développeurs pour rendre les sites Web interactifs.
Contrairement au HTML, le JavaScript permet d’animer dynamiquement le contenu d’une page. C’est notamment le cas lorsque vous utilisez les filtres sur un site E-commerce (exemple : ManoMano ou encore Cdiscount). Sans Javascript, le comportement serait différent puisque la page se rechargerait totalement au clic d’un filtre alors qu’avec le JS seul le contenu dans la page se recharge donnant ainsi une impression de fluidité.
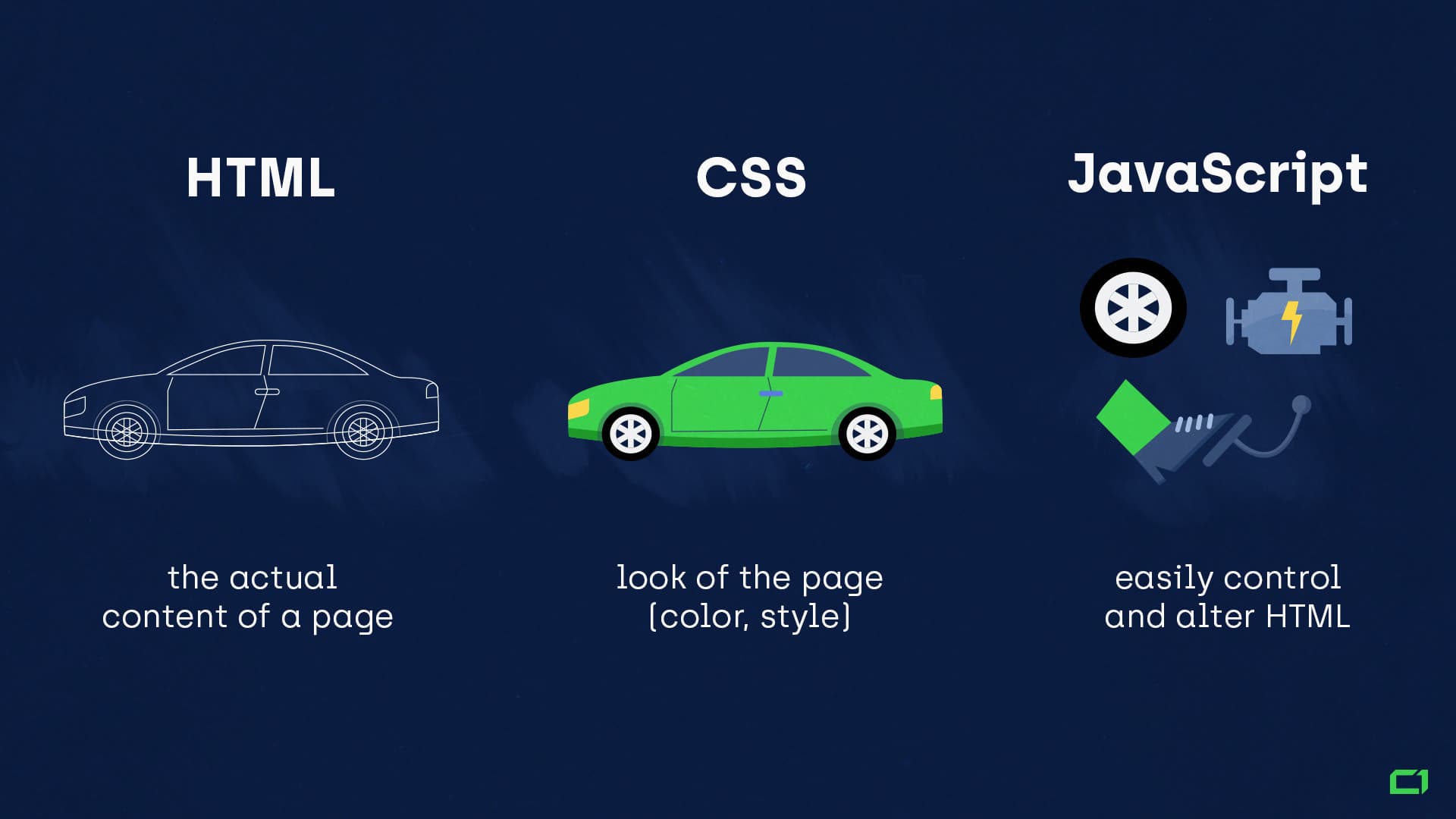
Pour bien comprendre comment s’articulent le Javascript avec le HTML et le CSS, considérons que :
- Le HTML définit le contenu réel d’une page (corps / cadre d’une voiture).
- CSS définit l’apparence de la page (couleurs, style).
- JavaScript ajoute de l’interactivité à la page. Il peut facilement contrôler et modifier le HTML (moteur + roue + pédales d’accélérateur).
Comment savoir si mon site utilise du JavaScript ?
Utilisez une extension chrome : WEB DEVELOPER
Pour vérifier facilement si votre site Web repose sur JavaScript, téléchargez l’extension chrome Web Developer (si vous utilisez Google Chrome) Une fois que c’est fait, rendez-vous dans la barre de votre navigateur puis :

En cliquant sur « Disable JavaScript » vous venez de désactiver le JS dans votre navigateur.
« OK super et qu’est-ce que je dois faire maintenant ? »
C’est simple :
- Vérifier si le (ou une partie) contenu de votre page n’a pas disparu
- Tester les liens de vos pages (exemple ici avec ManoMano et les filtres)
Si certains éléments de la page disparaissent, cela signifie qu’ils ont été générés par JavaScript.
Important : Une vérification du code source de la page ne suffit pas !
Dans le cadre d’un audit SEO autour du Javascript, vous entendrez peut-être que rechercher le contenu dans le code source de vos pages Web est l’une des choses les plus importantes.
Le code source (clic droit > Affichez le code source de la page) représente uniquement les informations brutes utilisées par le navigateur pour analyser la page. Il contient des balises représentant des paragraphes, des images, des liens et des références à des fichiers JS et CSS.
Cependant, en affichant la source de la page, vous ne verrez aucun contenu dynamique mis à jour par JavaScript.
Avec les sites Web JavaScript, vous devriez plutôt regarder le DOM. Vous pouvez le faire en cliquant avec le bouton droit -> Inspecter l’élément.
Voici comment je décrirais la différence entre le HTML initial et le DOM:
- Le code HTML initial (clic droit -> Afficher la source de la page) n’est qu’une recette de cuisine. Il fournit des informations sur les ingrédients que vous devez utiliser pour cuire un gâteau. Il contient un ensemble d’instructions. Mais ce n’est pas le vrai gâteau.
- DOM (clic droit -> inspecter l’élément) est le vrai gâteau. Au début, c’est juste une recette (un document HTML) puis, après un certain temps, il gagne un formulaire, puis il est cuit (page entièrement chargée)
Google + Javascript + SEO = compliqué ?
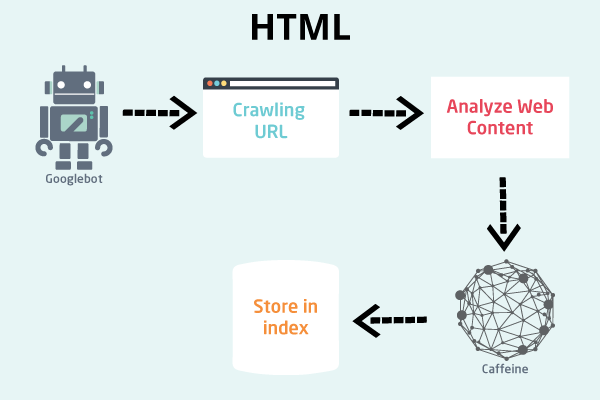
Exploration du contenu HTML vs contenu JavaScript
Dans le cas de l’exploration de sites Web HTML traditionnels, tout est simple et direct, et l’ensemble du processus est rapide comme l’éclair:
- Googlebot télécharge un fichier HTML .
- Googlebot extrait les liens du code source et peut les visiter simultanément.
- Googlebot télécharge les fichiers CSS.
- Googlebot envoie toutes les ressources téléchargées à l’indexeur de Google (caféine).
- L’indexeur (caféine) indexe la page.
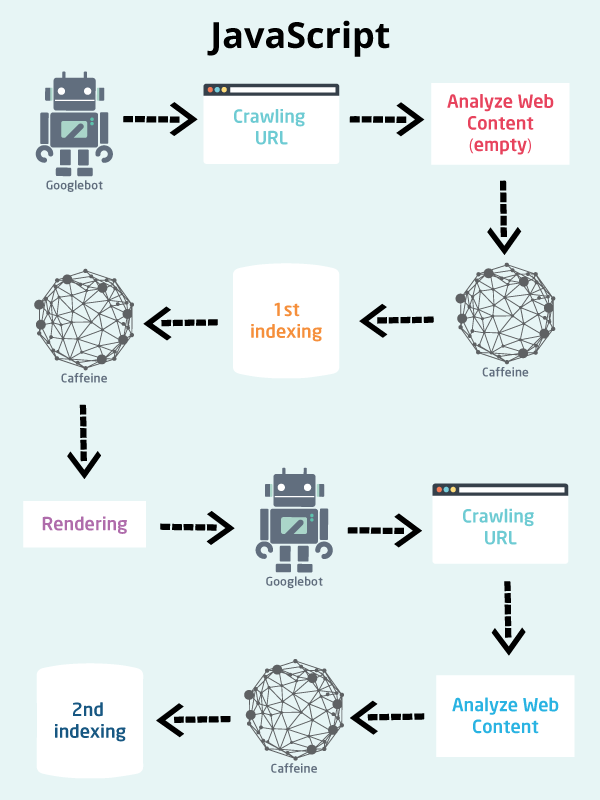
Pour Google, les choses se compliquent lorsqu’il s’agit d’explorer un site Web basé sur JavaScript:
- Googlebot télécharge un fichier HTML .
- Googlebot ne trouve aucun lien dans le code source car ils ne sont injectés qu’après l’exécution de JavaScript.
- Googlebot télécharge les fichiers CSS et JS.
- Googlebot doit utiliser le service de rendu Web de Google (une partie de l’indexer de caféine) pour analyser, compiler et exécuter JavaScript.
- WRS récupère les données des API externes, de la base de données, etc.
- L’indexer peut indexer le contenu.
- Google peut découvrir de nouveaux liens et les ajouter à la file d’attente d’exploration de Googlebot. Dans le cas du site Web HTML, c’est la deuxième étape.
Googlebot n’agit pas comme un vrai navigateur
Comme vous le savez peut-être, Googlebot est basé sur la dernière version de Chrome. Cela signifie que Googlebot utilise la version actuelle du navigateur pour le rendu des pages. Mais ce n’est pas exactement pareil. Explications !
Googlebot visite les pages Web comme un utilisateur le ferait avec un navigateur. Cependant, Googlebot n’est pas un navigateur Chrome ordinaire. Par exemple, les navigateurs téléchargent toujours toutes les ressources d’une page pour l’afficher correctement – Googlebot peut choisir de ne pas le faire.
La raison est simple : Parcourir le web est une tâche particulièrement complexe mais surtout couteuse. Par conséquent, Google optimise ses robots d’exploration. C’est pourquoi Googlebot ne charge parfois pas toutes les ressources du serveur.
Les algorithmes de Google tentent de détecter si une ressource donnée est nécessaire du point de vue du rendu. Si ce n’est pas le cas, il est possible qu’il ne soit pas récupéré par Googlebot. Google en avertit les webmasters dans la documentation officielle.
Googlebot et son composant Web Rendering Service (WRS) analysent et identifient en permanence les ressources qui ne contribuent pas au contenu essentiel de la page et peuvent ne pas récupérer ces ressources. source: documentation officielle de Google
D’après Martin Splitt, analyste des tendances pour les webmasters chez Google, Google peut décider qu’une page ne change pas beaucoup après le rendu (après l’exécution de JS), de sorte qu’ils ne le rendront pas à l’avenir.
De plus, le rendu de JavaScript par Google est toujours retardé (cependant, c’est beaucoup mieux qu’en 2017-2018, lorsque nous devions généralement attendre des semaines avant que Google ne rende JavaScript).
Si votre contenu nécessite que Google clique, fasse défiler ou effectue toute autre action pour qu’il apparaisse, il ne sera pas indexé.
Dernier point mais non le moindre: le moteur de rendu de Google a des délais d’expiration. Si le rendu de votre script prend trop de temps, Google peut simplement l’ignorer.
JavaScript + SEO : Quelles sont les bonnes pratiques ?
Vous savez maintenant que JavaScript rend le travail de Google un peu plus compliqué.
Faire du SEO sur un site dont le contenu est généré par du JavaScript peut sembler intimidant mais pas de panique, cette partie de l’article vous aidera à diagnostiquer les problèmes potentiels sur votre site Web et à obtenir les bonnes bases.
Comment s’assurer que Googlebot découvre bien le contenu des mes pages en JS ?
Voici une liste de contrôle que vous pouvez utiliser pour vérifier si Google et d’autres moteurs de recherche sont capables d’indexer votre contenu JavaScript.
I. Vérifiez si Google explorer le contenu de vos pages
En tant que développeur, propriétaire de site Web ou SEO, vous devez toujours vous assurer que Google peut rendre techniquement votre contenu JavaScript . Il ne suffit tout simplement pas d’ouvrir Chrome et de voir si c’est OK.
Utilisez plutôt le test en direct dans l’outil d’inspection d’URL de Google, disponible via la Search Console. Il vous permet de voir une capture d’écran de la façon dont Googlebot rendrait exactement le contenu JavaScript sur votre page.

Inspectez la capture d’écran et posez-vous les questions suivantes :
- Le contenu principal est-il visible?
- Google peut-il accéder à des zones telles que des articles et des produits similaires?
- Google peut-il voir d’autres éléments cruciaux de votre page?
Si vous souhaitez approfondir, vous pouvez également consulter l’ onglet HTML dans le rapport généré.
Ici, vous pouvez voir le DOM – le code rendu, qui représente l’état de votre page après le rendu.
Et si Google ne peut pas afficher correctement votre page ?
Il peut arriver que Google affiche votre page de manière inattendue. Il y a plusieurs raisons possibles à cela:
- Google a rencontré des délais d’attente lors du rendu.
- Des erreurs se sont produites lors du rendu.
- Vous avez bloqué des fichiers JavaScript cruciaux de Googlebot.
En cliquant sur l’ onglet Plus d’infos , vous pouvez facilement vérifier si des erreurs JavaScript se sont produites pendant que Google essayait de rendre votre contenu.
Remarque importante: s’assurer que Google peut rendre correctement votre site Web est une nécessité.
Cependant, cela ne garantit pas que votre contenu sera indexé. Ce qui nous amène au deuxième point.
II. Vérifiez si votre contenu est indexé dans Google.
Il existe deux façons de vérifier si votre contenu JavaScript est vraiment indexé dans Google.
- Utiliser la commande «site» – la méthode la plus rapide .
- Vérification de Google Search Console – la méthode la plus précise .
En bref: vous ne devez pas vous fier à la vérification de Google Cache pour vous assurer que Google indexe votre contenu JavaScript . Même si de nombreux référenceurs l’utilisent encore, c’est une mauvaise idée de s’appuyer sur Google Cache.
La commande Google «Site:»
En 2020, l’une des meilleures options pour vérifier si votre contenu est indexé par Google est la commande « site ». Vous pouvez le faire en deux étapes simples.
1. Vérifiez si la page elle-même est dans l’index de Google.
Tout d’abord, vous devez vous assurer que l’URL elle-même est dans l’index de Google. Pour ce faire, tapez simplement « site: URL » dans Google (où l’URL est l’adresse URL d’une page que vous souhaitez vérifier).

Si un extrait avec votre fragment apparaît, cela signifie que votre contenu est indexé dans Google.
Je vous encourage à vérifier la commande «site» sur différents types de contenu généré par JS.
Ma recommandation personnelle: effectuez une requête «site:» avec un fragment en mode navigation privée.
Que faire si Google n’indexe pas mon contenu généré par du JS ?
Il existe plusieurs raisons pour lesquelles votre contenu JavaScript n’a pas été récupéré par Google. Pour n’en nommer que quelques-uns:
- Google rencontre des délais d’attente . Êtes-vous sûr de ne pas forcer Googlebot et les utilisateurs à attendre plusieurs secondes avant de pouvoir voir le contenu?
- Google a eu des problèmes de rendu . Avez-vous vérifié l’outil d’inspection d’URL pour voir si Google peut le rendre?
- Google a décidé d’ignorer certaines ressources (par exemple, les fichiers JavaScript) .
- Google a décidé que le contenu était de mauvaise qualité.
- Il peut également arriver que Google indexe le contenu JavaScript avec un certain retard .
- Google n’a tout simplement pas pu découvrir cette page. Êtes-vous sûr qu’il est accessible via le plan du site et la structure interne? La page n’est-elle pas bloquée par le robots.txt ?
Différentes façons de présenter du contenu JavaScript pour Google
Il existe plusieurs façons de servir vos pages Web aux utilisateurs et aux moteurs de recherche. Deux grands principes existent : Le SSR (Server Side Rendering) et le CSR (Client Side Rendering).

SSR (Server Side Rendering)
Dans l’approche traditionnelle ( rendu côté serveur ), un navigateur ou Googlebot reçoit un fichier HTML qui décrit complètement la page. La copie du contenu est déjà là. Habituellement, les moteurs de recherche n’ont aucun problème avec le contenu JavaScript rendu côté serveur.
CSR (Client Side Rendering)
L’ approche du CSR (rendu côté client) est de plus en plus populaire mais est souvent source de catastrophe d’un point de vue SEO. Avec cette approche, il est assez courant qu’un navigateur ou Googlebot obtienne une page HTML vierge (avec peu ou pas de copie de contenu) lors du chargement initial. Puis la magie opère: JavaScript télécharge de manière asynchrone la copie de contenu depuis le serveur et met à jour votre écran.
Comment faire pour assurer l’exploration de son contenu généré par du Javascript ?
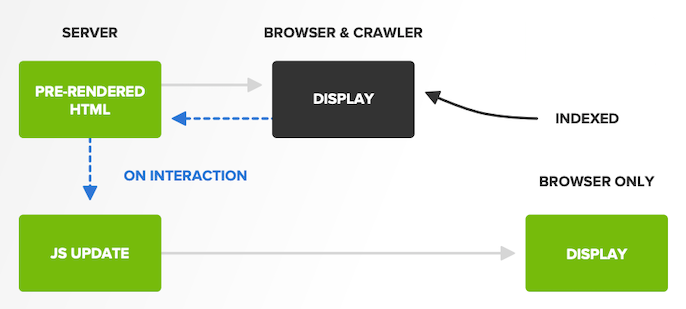
1. Le Pre-rendering
Le pre-rendering est une solution visant à envoyer à Googlebot une version HTML de la page, c’est-à-dire une version rendue du DOM, autrement dit ce que les gens voient. La complexité ici est de s’assurer que les moteurs de recherche reçoivent une représentation valide et précise de la page.
Avantages :
- Permet aux moteurs de recherche de voir du contenu immédiatement pour l’indexation.
Inconvénients :
- N’affiche pas le contenu complet.
- Sujette à des problèmes de chargement.
- Le contenu pré-rendu manque d’interactivité pour les utilisateurs.
2. Le SSR (Server Side Rendering)
Avec le rendu côté serveur, le serveur fait le gros du travail et restitue tout le JavaScript sur la page, ce qui signifie qu’il peut envoyer une page entièrement traitée directement au client. Le client n’a qu’à afficher le contenu fini. Le rendu côté serveur permet aux moteurs de recherche d’indexer votre contenu. Certaines solutions pour implémenter le rendu côté serveur sont Prerender.io , Universal , Puppeteer et Rendertron .
Avantages :
- Traite et envoie le contenu complet au client.
- La découverte de liens est plus rapide car le balisage est disponible rapidement pour les moteurs de recherche.
- Le contenu est disponible rapidement pour les utilisateurs.
- Augmente la vitesse et les performances du site.
Inconvénients :
- Une charge non négligeable pour les serveurs
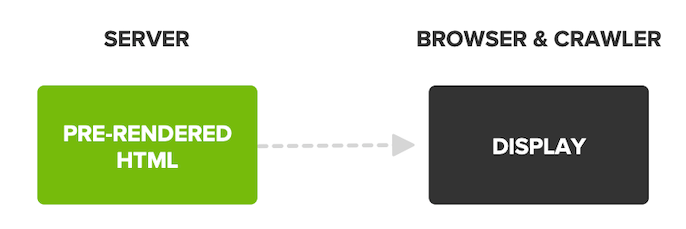
3. RENDU HYBRIDE
Le rendu hybride est un mix de SSR et CSR. Clarifions tout ça ! A travers le Rendu Hybride, le contenu principal de la page est restitué sur le serveur et envoyé au navigateur ou au moteur de recherche qui demande la page. Cela signifie que le client recevra toujours le contenu et le balisage rendus immédiatement.
Il y a une dernière étape dans ce processus pour les utilisateurs. Une fois le contenu de base affiché, du JavaScript supplémentaire est ensuite envoyé pour être rendu côté client afin que l’utilisateur puisse interagir avec la page.
Avantages :
- Contenu plus rapide et découverte de liens pour les moteurs de recherche.
- Le contenu est disponible plus rapidement pour les utilisateurs.
- Permet l’interactivité pour les utilisateurs.
Inconvénients :
- L’expérience pleine page n’est pas disponible sans un rendu côté client.
- Peut être complexe à mettre en œuvre.
- Peut entraîner des problèmes de vitesse car le rendu doit se produire deux fois.
2. RENDU DYNAMIQUE
Le rendu dynamique fonctionne en détectant l’user agent du client. Si l’user agent Googlebot est détecté, une version entièrement rendue de la page est envoyée. Tous les autres agents utilisateurs devront rendre JavaScript côté client.
Avantages :
- Le balisage est disponible rapidement pour les moteurs de recherche à indexer.
Inconvénients :
- Met plus de pression sur le serveur.
- Ajoute une autre couche de complexité pour les tests.
- Implique la gestion de 2 sites en parallèle (1 version pour Google et une version pour les internautes).

Voilà, si tu lis ces lignes c’est que l’article a été intéressant et j’espère enrichissant. Pour finir, Google fournit également un guide pratique expliquant comment réussir la mise en œuvre du rendu dynamique. Bonne chance !
